Key Insights for Big Data Curation
eScience and eGovernment are the innovators while biomedical and media companies are the early adopters: The demand for data interoperability and reuse on eScience, and the demand for effective transparency through open data in the context of eGovernment are driving data curation practices and technologies. These sectors play the roles of visionaries and innovators in the data curation technology adoption lifecycle. From the industry perspective, organisations in the biomedical space, such as pharmaceutical companies, play the role of early-adopters, driven by the need to reduce the time-to-market and lower the costs of the drug discovery pipelines. Media companies are also early adopters, driven by the need to organise large unstructured data collections, to reduce the time to create new products, repurposing existing data, and to improve accessibility and visibility of information artefacts.
The core impact of data curation is to enable more complete and high-quality data-driven models for knowledge organisations: More complete models support a larger number of answers through data analysis. Data curation practices and technologies will progressively become more present in contemporary data managementenvironments, facilitating organisations and individuals to reuse third party data in different contexts, reducing the barriers for generating content with high data quality. The ability to efficiently cope with data quality and heterogeneity issues at scale will support data consumers on the creation of more sophisticated models, highly impacting the productivity of knowledge-driven organisations.
Data curation depends on the creation of an incentives structure: As an emergent activity, there is still vagueness and poor understanding on the role of data curation inside the big data lifecycle. In many projects the data curation costs are not estimated or are underestimated. The individuation and recognition of the data curator role and of data curation activities depends on realistic estimates of the costs associated with producing high quality data. Funding boards can support this process by requiring an explicit estimate of the data curation resources on public funded projects with data deliverables and by requiring the publication of high-quality data. Additionally, the improvement of the tracking and recognition of data and infrastructure as a first-class scientific contribution is also a fundamental driver for methodological and technological innovation for data curation and for maximizing the return of investment and reusability of scientific outcomes. Similar recognition is needed within the enterprise context.
Emerging economic models can support the creation of data curation infrastructures: Pre-competitive and public-private partnerships are emerging economic models that can support the creation of data curation infrastructures and the generation of high-quality data. Additionally, the justification for the investment on data curation infrastructures can be supported by a better quantification of the economic impact of high-quality data.
Curation at scale depends on the interplay between automated curation platforms and collaborative approaches leveraging large pools of data curators: Improving the scale of data curation depends on reducing the cost per data curation task and increasing the pool of data curators. Hybrid human-algorithmic data curation approaches and the ability to compute the uncertainty of the results of algorithmic approaches are fundamental for improving the automation of complex curation tasks. Approaches for automating data curation tasks such as curation by demonstration can provide a significant increase in the scale of automation. Crowdsourcing also plays an important role in scaling-up data curation, allowing access to large pools of potential data curators. The improvement of crowdsourcing platforms towards more specialized, automated, reliable and sophisticatedplatforms and the improvement of the integration between organizational systems and crowdsourcing platforms represent an exploitable opportunity in this area.
The improvement of human-data interaction is fundamental for data curation: Improving approaches in which curators can interact with data impacts curation efficiency and reduces the barriers for domain experts and casual users to curate data. Examples of key functionalities in human-data interaction include: natural language interfaces, semantic search, data summarization & visualization, and intuitive data transformation interfaces.
Data-level trust and permission management mechanisms are fundamental to supporting data management infrastructures for data curation: Provenance management is a key enabler of trust for data curation, providing curators the context to select data that they consider trustworthy and allowing them to capture their data curation decisions. Data curation also depends on mechanisms to assign permissions and digital rights at the data level.
Data and conceptual model standards strongly reduce the data curation effort: A standards-based data representation reduces syntactic and semantic heterogeneity, improving interoperability. Data model and conceptual model standards (e.g. vocabularies and ontologies) are available in different domains. However, their adoption is still growing.
Need for improved theoretical models and methodologies for data curation activities. Theoretical models and methodologies for data curation should concentrate on supporting the transportability of the generated data under different contexts, facilitating the detection of data quality issues and improving the automation of data curation workflows.
Better integration between algorithmic and human computation approaches: The growing maturity ofdata-driven statistical techniques in fields such as Natural Language Processing (NLP) and Machine Learning (ML) is shifting their use from academic into industry environments. Many NLP and ML tools have uncertainty levels associated with their results and are dependent on training over large datasets. Better integration between statistical approaches and human computation platforms is essential to allow the continuous evolution of statistical models by the provision of additional training data and also to minimize the impact of errors in the results.
Emerging Requirements for Big Data Curation
Many big data scenarios are associated with reusing and integrating data from a number of different data sources. This perception is recurrent across data curation experts and practitioners and it is reflected in statements such as: “a lot of big data is a lot of small data put together”, “most of big data is not a uniform big block”, “each data piece is very small and very messy, and a lot of what we are doing there is dealing with that variety” (Data Curation Interview: Paul Groth, 2013).
Reusing data that was generated under different requirements comes with the intrinsic price of coping with data quality and data heterogeneity issues. Data can be incomplete or may need to be transformed in order to be rendered useful. Kevin Ashley, director of Digital Curation Centre summarizes the mind-set behind data reuse: “… [it is] when you simply use what is there, which may not be what you would have collected in an ideal world, but you may be able to derive some useful knowledge from it” (Data Curation Interview: Kevin Ashley, 2013). In this context, data shifts from a resource that is tailored from the start to a certain purpose, to a raw material that will need to be repurposed in different contexts in order to satisfy a particular requirement.
In this scenario data curation emerges as a key data management activity. Data curation can be seen from a data generation perspective (curation at source), where data is represented in a way that maximizes its quality in different contexts. Experts emphasize this as an important aspect of data curation: from the data science aspect, methodologies are needed to describe data so that it is actually reusable outside its original context (Data Curation Interview: Kevin Ashley, 2013). This points to the demand to investigate approaches which maximize the quality of the data in multiple contexts with a minimum curation effort: “we are going to curate data in a way that makes it usable ideally for any question that somebody might try to ask the data” (Data Curation Interview: Kevin Ashley, 2013). Data curation can also be done at the data consumption side where data resources are selected and transformed to fit a set of requirements from the data consumption side.
Data curation activities are heavily dependent on the challenges of scale, in particular data variety, that emerges in the big data context. James Cheney, research fellow at the University of Edinburgh, observes “Big Data seems to be about addressing challenges of scale, in terms of how fast things are coming out at you versus how much it costs to get value out of what you already have”. Coping with data variety can be costly even for smaller amounts of data: “you can have Big Data challenges not only because you have Petabytes of data but because data is incredibly varied and therefore consumes a lot of resources to make sense of it”.
While in the big data context the expression data variety is used to express the data management trend of coping with data from different sources, the concepts of data quality (Wang & Strong, 1996; Knight & Burn, 2005) and data heterogeneity (Sheth, 1999) have been well established in the database literature and provide a precise ground for understanding the tasks involved in data curation.
Despite the fact that data heterogeneity and data quality were concerns already present before the big data scale era (Wang & Strong, 1996; Knight & Burn, 2005), they become more prevalent in data management tasks with the growth in the number of data sources. This growth brought the need to define principles and scalable approaches for coping with data quality issues. It also brought data curation from a niche activity, restricted to a small community of scientists and analysts with high data quality standards, to a routine data management activity, which will progressively become more present within the average data management environment.
The growth in the number of data sources and the scope of databases defines a long tail of data variety (Curry & Freitas, 2014). Traditional relational data management environments were focused on data that mapped to frequent business processes and were regular enough to fit into a relational model. The long tail of data variety (see Figure below) expresses the shift towards expanding the data coverage of data management environments towards data that is less frequently used, more decentralized, and less structured. The long tail allows data consumers to have a more comprehensive model of their domain that can be searched, queried, analysed and navigated.
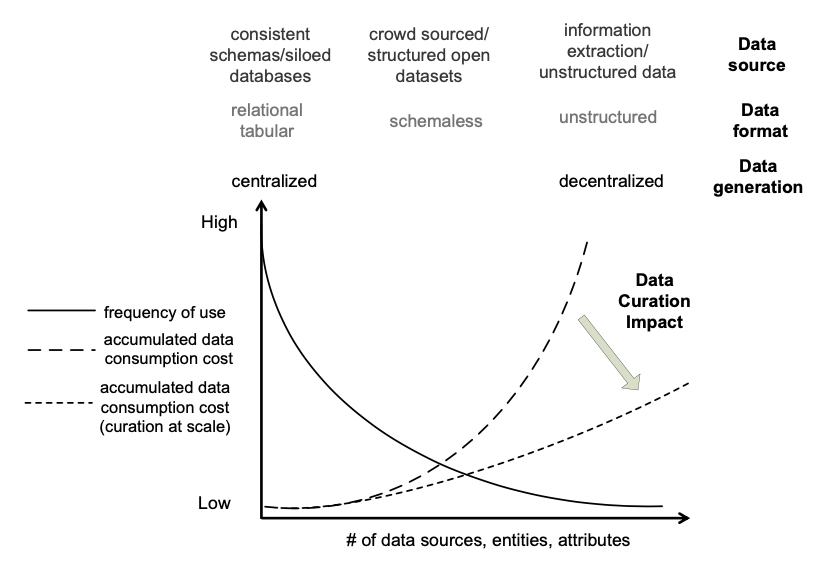
The central challenge of data curation models in the big data era is to deal with the long tail of data and to improve data curation scalability, by reducing the cost of data curation and increasing the number of data curators, allowing data curation tasks to be addressed under limited time constraints.
Scaling up data curation is a multidisciplinary problem that requires the development of economic models, social structures, incentive models, and standards, in coordination with technological solutions. The connection between these dimensions and data curation scalability is at the centre of the future requirements and future trends for data curation.
Excerpt from: Freitas, A. and Curry, E. (2016) ‘Big Data Curation’, in Cavanillas, J. M., Curry, E., and Wahlster, W. (eds) New Horizons for a Data-Driven Economy: A Roadmap for Usage and Exploitation of Big Data in Europe. Springer International Publishing. doi: 10.1007/978-3-319-21569-3_6.
References
- Curry, E., Freitas, A., & O’Riáin, S., The Role of Community-Driven Data Curation for Enterprise. In D. Wood, Linking Enterprise Data pp. 25-47, (2010).
- Knight, S.A., Burn, J., Developing a Framework for Assessing Information Quality on the World Wide Web. Informing Science. 8: pp. 159-172, 2005.
- Sheth, A., Changing Focus on Interoperability in Information Systems: From System, Syntax, Structure to Semantics, Interoperating Geographic Information Systems The Springer International Series in Engineering and Computer Science Volume 495, pp 5-29, (1999).
- Wang, R., Strong, D., Beyond Accuracy: What Data Quality Means to Data Consumers. Journal of Management Information Systems, 12(4): p. 5-33, (1996).