Big Data Roadmap for Energy and Transport
The big data value chain for infrastructure- and resource-centric systems of energy and transport businesses consists of three main phases: data acquisition, data management, and data usage. Data analytics, as indicated by business user needs, is implicitly required within all steps, and is not a separate phase:
The technology roadmap for fulfilling the key requirements along the data value chain for the Energy and Transport sectors focuses on technology that is not readily available and needs further research and development in order to fulfil the strict requirements of Energy and Transport applications.
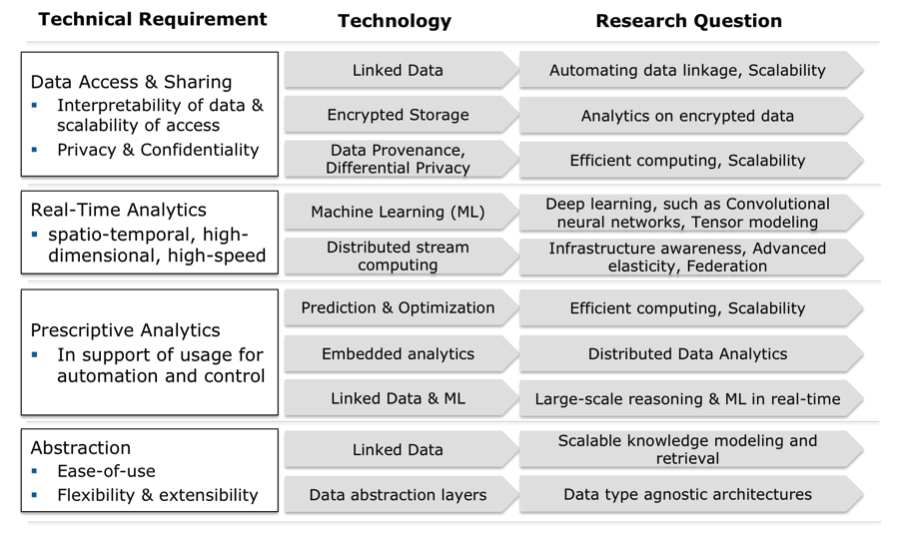
Data Access & Sharing
Energy and transport are resource-centric infrastructure businesses. Access to usage data creates the opportunity to analyse the usage of a product or service to improve it, or gain efficiency in sales and operations. Usage data needs to be combined with other available data to deliver reliable predictive models. Currently there is a trade-off between enhancing interpretability of data and preserving privacy & confidentiality. The following example of mobility usage data combined with a variety of other data demonstrates the privacy challenge. De Montjoye et al, (2014) showthat “4 spatio-temporal points, (approximate places and times), are enough to uniquely identify 95% of 1.5M people in a mobility database. The study further states that these constraints hold even when the resolution of the dataset is low”. The work shows that mobility datasets combined with metadata can circumvent anonymity.
At the same time, insufficient privacy protection options can hinder the sourcing of big data in the first place, as experiences from smart metering rollouts in the energy businesses show. In the EU only 10 percent of homes have smart meters (Nunez, 2012). Although there is a mandate that the technology reaches 80 percent of homes by 2020, European rollouts are stagnant. A survey from 2012 (Department of Energy & Climate Change, 2012) finds that “with increasing reading frequency, i.e. from monthly to daily, to half hourly, etc., energy consumption data did start to feel more sensitive as the level of detail started to seem intrusive… Equally, it was not clear to some [participants] why anyone would want the higher level of detail, leaving a gap to be filled by speculation which resulted in some [participants] becoming more uneasy.”
Advances are needed for the following technologies for data access and sharing:
- Linked Data is a lightweight practice for exposing and connecting pieces of data, information, or knowledge using basic web standards. It promises to open up siloed data ownership and is already an enabler of open data and data sharing. However, with the increasing number of data sources already linked, the various types of new data that will come from intelligent infrastructures, and always connected end users in energy and mobility, scalability and cost-efficacy becomes an issue. One of the open research questions is how to (semi-)automatically extract data linkage to increase current scalability.
- Encrypted Data Storage can enable integrated, data-level security. As cloud storage becomes commonplace for domestic and commercial end users, better and more user-friendly data protection becomes a differentiation factor (Tanner, 2014). In order to preserve privacy and confidentiality the use of encrypted data storage will be a basic enabler of data sharing and shared analytics. However, analytics on encrypted data is still an on-going research question. The most widely pursued research is called fully-homomorphic encryption. Homomorphic encryption theoretically allows operations to be carried out on the cipher text. The result is a cipher text that when decrypted matches the result of operation on plaintext. Currently only basic operations are feasible.
- Data Provenance is the art of tracking data through all transformations, analyses, and interpretations. Provenance assures that data that is used to create actionable insights are reliable. The metadata that is generated to realize provenance across the big variety of datasets from differing sources also increases interpretability of data, which in turn could improve automated information extraction. However, scaling data provenance across the dimensions of big data is an open research question.
- Differential Privacy (Dwork, 2014) is the mathematically rigorous definition of privacy (and its loss) with the accompanying algorithms. The fundamental law of information recovery (Dwork, 2014) states that too many queries with too few errors will expose the real information. The purpose of developing better algorithms is to push this event as far away as possible. This notion is very similar to the now mainstream realization that there is no unbreakable security, but that barriers if broken need to be fixed and improved. The cutting edge research on differential privacy considers distributed databases and computations on data streams, enabling linear scalability and real-time processing for privacy preserving analytics. Hence, this technique could be an enabler of privacy preserving analytics on big data, allowing big data to gain user acceptance in mobility and energy.
Real-Time & Multi-Dimensional Analytics
Real-time & multi-dimensional analytics enable real-time, multi-way analysis of streaming, spatio-temporal energy and transport data. Examples from dynamic complex cyber-physical systems such as power networks show that there is a clear business mandate. Global spending on power utility data analytics is forecast to top $20 billion over the next nine years, with an annual spend of $3.8 billion globally by 2020 (GTM Research, 2012). However cost-efficacy of the required technologies needs to be proven. Real-time monitoring does not justify the cost if actions cannot be undertaken in real-time. Phasor measurement technology, enabling high-resolution views of the current status of power networks in real-time is a technology that was invented 30 years ago. Possible applications have been researched for more than a decade. Initially there was no business need for it, because the power systems of the day were well engineered and well structured, hierarchical, static, and predictable. With increased dynamics through market liberalization and the integration of power generation technology from intermittent renewable sources like wind and solar, real-time views of power networks becomes indispensible.
Advances are needed for the following technologies:
- Distributed Stream Computing is currently gaining traction. There are two different strains of research and development of stream computing: 1) stream computing as in complex event processing (CEP), which has had its main focus on analyzing data of high-variety and high-velocity, and 2) distributed stream computing, focusing on high-volume and high-velocity data processing. Complementing the missing third dimension, volume and variety respectively in both strains is the current research direction. It is argued that distributed stream computing, which already has linear scalability and real-time processing capabilities, will tackle high-variety data challenges with semantic techniques (Hasan and Curry 2014) and Linked Data. A further open question is how to ease development and deployment for the algorithms that make use of distributed stream computing as well as other computing and storage solutions, such as plain old data warehouses and RDBMS. Since cost-effectiveness is the main enabler for big data value, advanced elasticity with computing and storage on demand as the algorithm requires must also be tackled.
- Machine learning is a fundamental capability needed when dealing with big data and dynamic systems, where a human could not possibly review all data, or where humans just lack the experience or ability to be able to define patterns. Systems are becoming increasingly more dynamic with complex network effects. In these systems humans are not capable of extracting reliable cues in real-time – but only in hindsight during post-mortem data analysis (which can take significant time when performed by human data scientists). Deep learning, a research field that is gaining momentum, concentrates on more complex non-linear data models and multiple transformations of data. Some representations of data are better for answering a specific question than others, meaning multiple representations of the same data in different dimensions may be necessary to satisfy an entire application. The open questions are how to represent specific energy and mobility data, possibly in multiple dimensions. How to design algorithms that learn the answers to specific questions from the energy and mobility domains better than human operators of these systems can – and doing so in a verifiable manner. The main questions for machine learning are cost-effective storage and computing for massive amounts of high-sampled data, the design of new efficient data structures, and algorithms such as tensor modelling and convolutional neural networks.
Prescriptive analytics
Prescriptive analytics enable real-time decision automation in energy and mobility systems. The more complex and dynamic the systems are becoming, the faster insights from data will need to be delivered to enhance decision-making. With increasing ICT installed into the intelligent infrastructures of Energy and Transport, decision automation becomes feasible. However, with the increasing digitization, the normal operating state, when all digitized field devices deliver actionable information on how to operate more efficiently, will overwhelm human operators. The only logical conclusion is to either have dependable automated decision algorithms, or ignore the insights per second that a human operator cannot reasonably handle at the cost of reduced operational efficiency.
Advances are needed for the following technologies:
- Prescriptive Analytics: Technologies enabling real-time analytics are the basis for prescriptive analytics in cyber-physical systems with resource-centric infrastructures such as energy and transport. With prescriptive analytics the simple predictive model is enhanced with possible actions and their outcomes, as well as an evaluation of these outcomes. In this manner, prescriptive analytics not only explains what might happen, but also suggests an optimal set of actions. Simulation and optimization are analytical tools that support prescriptive analytics.
- Machine Readable Engineering and System Models: Currently many system models are not machine-readable. Engineering models on the other hand are semi-structured because digital tools are increasingly used to engineer a system. Research and innovation in this area of work will assure that machine learning algorithms can leverage system know-how that today is mainly limited to humans. Linked Data will facilitate the semantic coupling of know-how at design and implementation time, with discovered knowledge from data at operation time, resulting in self-improving data models and algorithms for machine learning (Curry E, et al 2013).
- Edge Computing: Intelligent infrastructures in the energy and mobility sectors have ICT capability built-in, meaning, there is storage and computing power along the entire cyber-physical infrastructure of electricity and transportation systems, not only in the control rooms and data centres at enterprise-level. Embedded analytics, and distributed data analytics, facilitating the in-network and in-field analytics (sometimes referred to as edge-computing) in conjunction with analytics carried out at enterprise-level will be the innovation trigger in energy and transport.
Abstraction
Abstraction from the underlying big data technologies is needed to enable ease of use for data scientists, and for business users. Many of the techniques required for real-time, prescriptive analytics, such as predictive modelling, optimization, and simulation are data and compute intensive. Combined with big data these require distributed storage and parallel, or distributed computing. At the same time many of the machine learning and data mining algorithms are not straightforward to parallelize. A recent survey (Paradigm 4, 2014) found that “although 49% of the respondent data scientists could not fit their data into relational databases anymore, only 48% have used Hadoop or Spark – and of those 76% said they could not work effectively due to platform issues.”
This is an indicator that big data computing is too complex to use without sophisticated computer science know-how. One direction of advancement is for abstractions and high-level procedures to be developed that hide the complexities of distributed computing and machine learning from data scientists. The other direction of course will be more skilled data scientists, who are literate in distributed computing, or distributed computing experts becoming more literate in data science and statistics. Advances are needed for the following technologies:
- Abstraction is a common tool in computer science. Each technology at first is cumbersome. Abstraction manages complexity so that the user (e.g. programmer, data scientist, or business user) can work closer to the level of human problem solving, leaving out the practical details of realization. In the evolution of big data technologies several abstractions have already simplified the use of distributed file systems by extracting SQL-like querying languages to make them similar to database, or by adapting the style of processing to that of familiar online analytical processing frameworks.
- Linked Data is one state-of-the-art enabler for realizing an abstraction level over large-scale data sources. The semantic linkage of data without priori knowledge and continuously linking with discovered knowledge is what will allow scalable knowledge modelling and retrieval in a big data setting. A further open question is how to manage a variety of data sources in a scalable way. Future research should establish a thorough understanding of data type agnostic architectures.
Excerpt from: Rusitschka, S. and Curry, E. (2016) ‘Big Data in the Energy and Transport Sectors’, in Cavanillas, J. M., Curry, E., and Wahlster, W. (eds) New Horizons for a Data-Driven Economy: A Roadmap for Usage and Exploitation of Big Data in Europe. Springer International Publishing. doi: 10.1007/978-3-319-21569-3_13.
References
- Adam Tanner. (2012, July 11). “The Wonder (And Woes) Of Encrypted Cloud Storage”. [Online Article]. Available: http://www.forbes.com/sites/adamtanner/2014/07/11/the-wonder-and-woes-of-encrypted-cloud-storage/
- Curry E, O’Donnell J, Corry E, et al (2013) Linking building data in the cloud: Integrating cross-domain building data using linked data. Adv Eng Informatics 27:206–219.
- Christina Nunez. (2012, December 12). “Who’s Watching? Privacy Concerns Persist as Smart Meters Roll Out”. [Online Article]. Available: http://news.nationalgeographic.com/news/energy/2012/12/121212-smart-meter-privacy/
- Cynthia Dwork, Aaron Roth. (2014). “The Algorithmic Foundations of Differential Privacy”. Foundations and Trends in Theoretical Computer Science Vol. 9, Nos. 3–4 (2014) 211–407. DOI: 10.1561/0400000042
- de Montjoye, Yves-Alexandre, César A. Hidalgo, Michel Verleysen, Vincent D. Blondel (2013, March 25). “Unique in the Crowd: The privacy bounds of human mobility”. Nature srep. doi:10.1038/srep01376.
- Department of Energy and Climate Change. (2012, December). “Smart Metering Data Access and Privacy – Public Attitudes Research”. [Whitepaper]. Available: https://www.gov.uk/government/uploads/system/uploads/attachment_data/file/43045/7227-sm-data-access-privacy-public-att.pdf
- GTM Research. (December 2012). The Soft Grid 2013-2020: Big Data & Utility Analytics for Smart Grid. [Online]. Available: www.sas.com/news/analysts/Soft_Grid_2013_2020_Big_Data_Utility_Analytics_Smart_Grid.pdf
- Hasan, Souleiman, and Edward Curry. 2014b. “Thematic Event Processing.” In Proceedings of the 15th International Middleware Conference on – Middleware ’14, 109–20. New York, New York, USA: ACM Press. doi:10.1145/2663165.2663335.
- Paradigm 4. (2014, July 1). “Leaving Data on the Table: New Survey Shows Variety, Not Volume, is the Bigger Challenge of Analyzing Big Data”, Survey. Available: http://www.paradigm4.com/wp-content/uploads/2014/06/P4PR07012014.pdf